.pptx
paper2slides
Pull key points, set the layout, place figures — an end-to-end deck you can present as-is.
Turn one academic paper into slides, a poster, a project page, Xiaohongshu & WeChat posts.

↑ All generated by paper2anything
Each subdirectory is a standalone, auto-triggered skill. They share one environment and credentials; workflows, outputs and publishing stay independent.
Pull key points, set the layout, place figures — an end-to-end deck you can present as-is.

Pick figures, set columns, hand-lay it out, then refine with visual and blind-review checks — a poster ready for the conference hall.
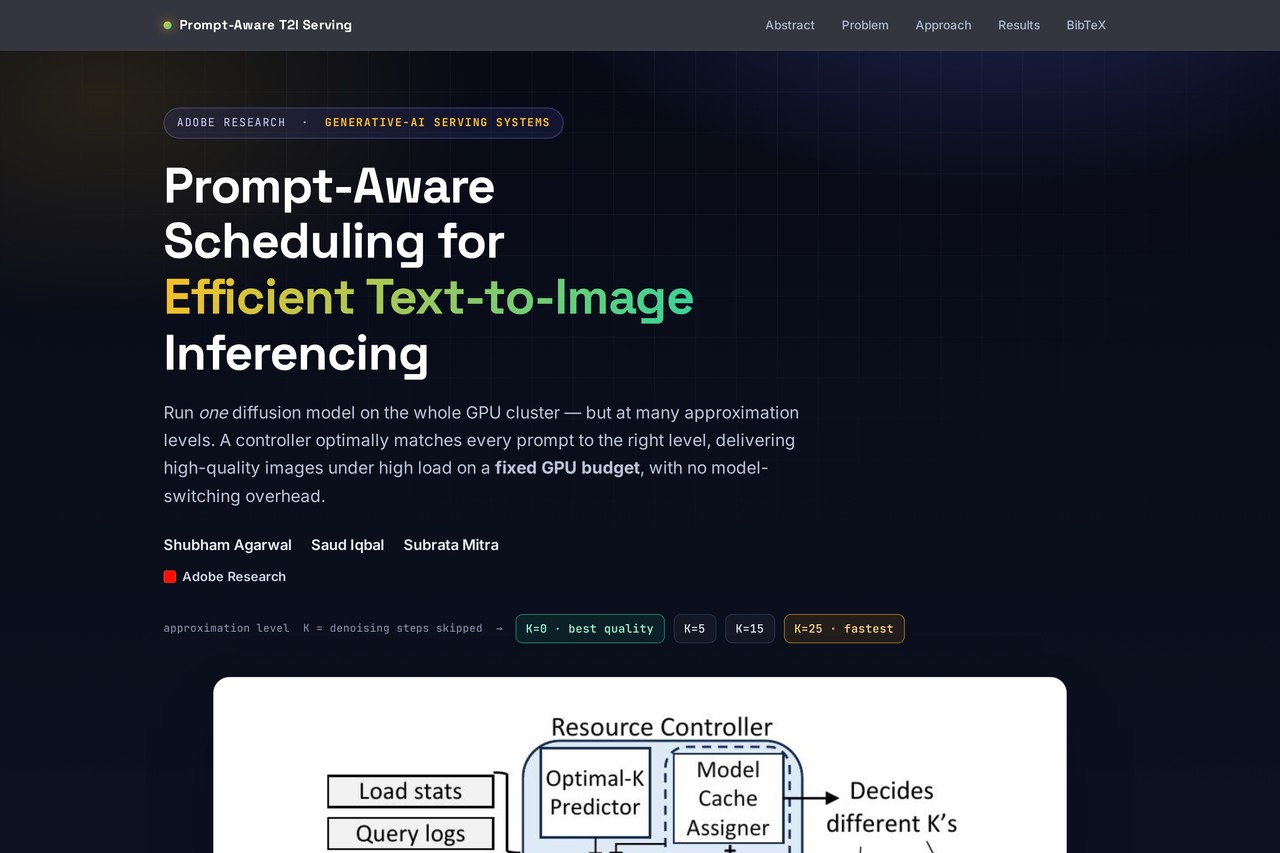
Build a deploy-ready single-page project site — a landing page for GitHub Pages.

Frame the angle, write title, body and tags, auto-generate a vertical cover, and post on-account after you confirm.

Outline it, write a deep-dive long read, add figures and a cover, push to the WeChat drafts in one go.
Every image below comes from a full run on a real paper — not cherry-picked, shown as-is.

No templates, no clones. Each paper is read on its own and picks colors, layout and figures that fit its character.
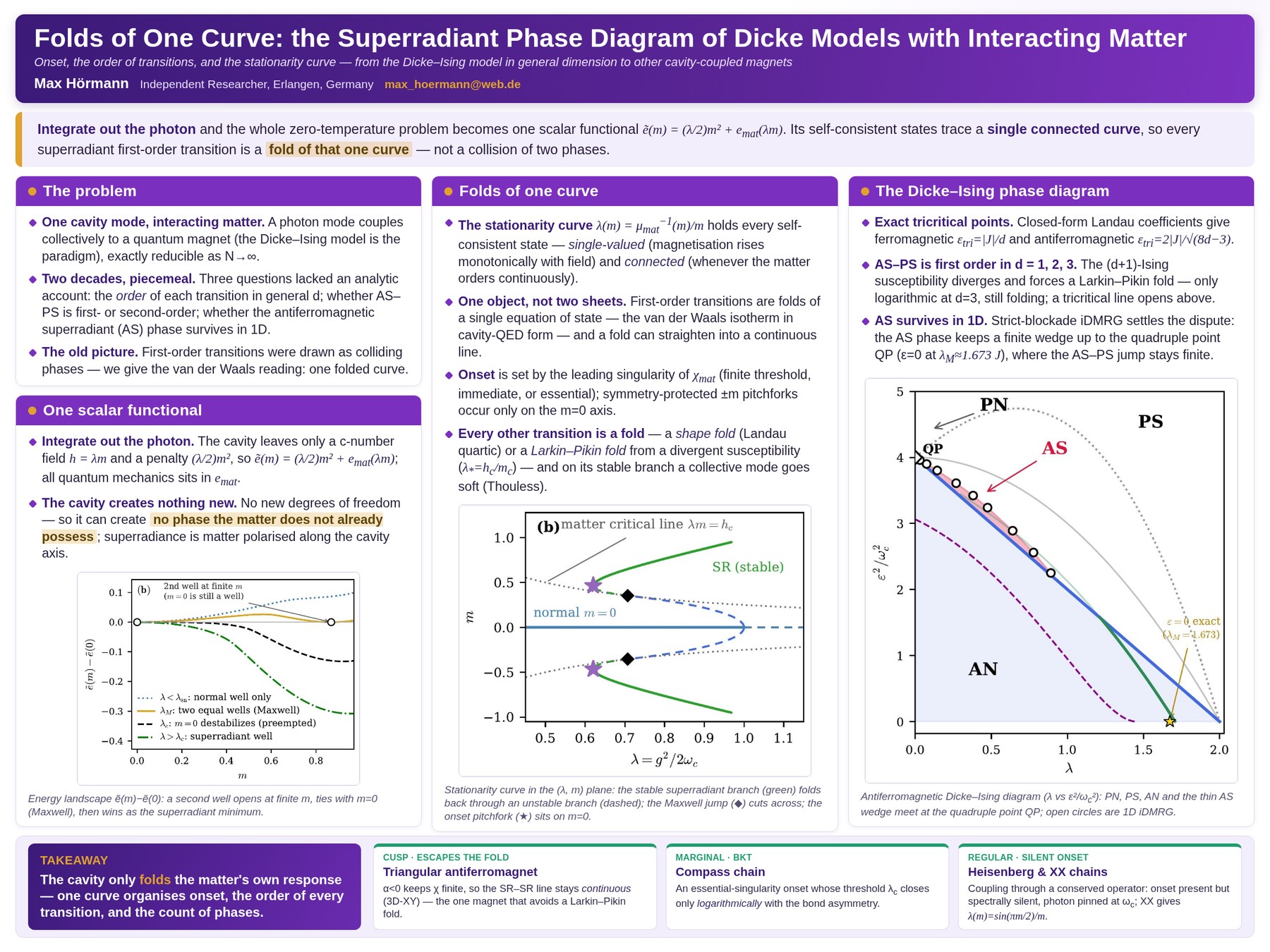
Multi-column layout with hand-placed figures and equations, refined via geometry checks and blind review. Exported as high-res PNG and editable HTML.

A self-contained single-page site: inline styles, relative-path figures, responsive layout, passing QA at desktop and mobile widths. Open it and go — push to GitHub Pages to ship.


Turn hardcore papers into Chinese social language: catchy titles, readable copy, plus auto-generated vertical / horizontal covers. Can post straight to Xiaohongshu, WeChat to drafts.
Every skill is agent-led and coordinated: parsing, figure-cropping and publishing call small tools; understanding the paper, designing the layout and writing the copy are done by the agent, confirming with you at key points.
Give a path, or just say what you want.
›Cloud-parsed into structured text and figures, with figures re-cropped in high definition.
›Reads the paper, sets direction, writes the product by hand, confirms at key points.
›Checks missing figures / broken links / render distortion / content fidelity, fixed to zero per report.
›The final product is copied next to the PDF — open and use.
Same skill, but every paper gets a design built from scratch — palette, structure and layout all differ; the same template is never reused.
Numbers, authors and citations come only from the parsed source; gaps are filled by the agent reading the full paper, never invented.
Each product is rendered to an image and picked apart by a blind-review agent — missing figures, distortion, overflow, fidelity — looped until zero.
Every skill carries its own design language and layout taboos — what to do and what never to do — so outputs avoid generic templates and AI slop.
The matching skill triggers automatically. Either way works:
"Make slides from paper.pdf"
"Make a conference poster from this paper"
"Turn this PDF into a project page"
"Post this paper to Xiaohongshu"
"Write this paper up for WeChat"
/paper2slides path/to/paper.pdf /paper2poster path/to/paper.pdf /paper2html path/to/paper.pdf /paper2xhs path/to/paper.pdf /paper2wechat path/to/paper.pdf
git clone https://github.com/QuZhan51496/paper2anything.git && cd paper2anything bash tools/install-linux.sh --create-env --shell-init # Linux bash tools/install-macos.sh --create-env --shell-init # macOS